[12] TRON 仕様コードは、 BTRON で使われている符号化文字集合です。
[13] 符号化方式は特別な符号列によって符号平面を切り替える ISO/IEC 2022 のような戦略を採用しています。 もっとも ISO/IEC 2022 は情報交換用の符号ですが、 TRON コードはそうではありません。
[99] TRON コードは 文字コードの一種ですが、 BTRON には平文に相当する概念が無いので、 可変長セグメントのようなものが含まれていたりもします。
[3] 8ビット空間又は16ビット空間を面と呼び、 同時に使用する文字群の1単位とします。 面は言語指定コードによって切り替えます。
[112] 面は 0x21 を第1面とし、以後十進数で表記されているようです。
[4] 8ビットの面は仕様上存在するだけで実際には使われていないそうです。
なお、ISO/IEC 646など、8ビット系コードとの互換は、「TRON1バイト文字コード」[2]「Eゾーン」[3]などとして一部の資料に言及が見られるが、制御コード以外は実装されていない。
[5] 16ビットの面は、あらゆるビット組合せを使うのではなく、 制御文字に相当する部分 (CL など) を避けています。
上\下 00 20 7E 80 A0 FD FE FF
00 +-------+--------+-+--+-+--------+
01 +-------+ +-+ +-+ |
| |
20 | +--------+ +---------+ |
| |A | |C | |
| | | | | |
| | | | | |
7E | +--------+ +---------+ |
80 | +--------+ +---------+ |
| |B | |D | |
| | | | | |
FD | | | | | |
FE | +--------+ +---------+--+
FF +-------+--------+--+------------+[6] どこかで聞いたことがある話だと思ったあなた! そう、 DIS 10646 そっくりです。 (DIS 10646 は CR も避けていますが、 TRON は CR も使っています。)
[101] 各符号平面は16ビットで、制御文字と同じバイトを避けて 4つの領域に分けられています。 四分区から成る平面を切り替えて使うというアイデアはまさに今はなき DIS 10646 とそっくりです。
[98] もっともこれはDECの文字コードなど同時代の他の文字コード体系とも共通した特徴です。 ISO/IEC 2022 → EUC → という自然な発展形態なのでしょう。
[587] どうせ16ビット符号なので害があるとも思われず CLも使ってしまえば、 と思ってしまうのは現代人だからで、 平成初期の人にとっては何となく何が起こるかわからず怖いから一応避けておこうというのが普通の感覚だったように見えますね。思い切って全部使うことにした Unicode があの時代にしては異常。
[588] TRONコードも16ビット符号だけに絞りきれずに8ビット符号を仕様上は残してあるようなので、 それとの兼ね合いもあったのかもしれませんけど、 制御コードの上位では 0x00 バイトを使っちゃってます。 0x00 を平気で使えるくらいなら、他の CL のバイトも使ってしまって困らなそうではあるんですよね。
[207] ただし 0xFE が使えないことには注意。このため GR (EUC の多バイト符号) と同じ符号で942集合を扱えません。 純粋技術的にはどうということはないのですが、 実際上 (人間が符号表を見ながら入力するとか、 変換プログラムを書くとか) はこの違いが面倒くささを将来しています。
[10] 文字コードの領域 (図形文字が割当てられ得る領域) は16ビットの1面に4つあり、合計で48400符号位置/面あります。
| 領域 | 名称 | 符号位置数 |
|---|---|---|
0x2121〜0x7E7E | Aゾーン | 8836 (94 × 94) |
0x8021〜0xFD7E | Bゾーン | 11844 (126 × 94) |
0x2180〜0x7EFD | Cゾーン | 11844 (94 × 126) |
0x8080〜0xFDFD | Dゾーン | 15876 (126 × 126) |
[102] 942以上のサイズという点に注目。 既存の942集合をそのまま収容できるだけでなく、それより大きな集合も入る。
[589] Aゾーンは ISO/IEC 2022 の GL に2バイト符号を呼び出しした状態と概念的には同じです。 Dゾーンは GR と同じになりそうなものですが、範囲が微妙に違うため、 同じビット組合せに配置することができません。
[590] この設計は、TRONコードを扱うプログラムを書いてみると思った以上に心理的な面倒臭さを感じます。 ISO/IEC 2022 の呼び出しは MSB のビット操作だけで GL / GR を切り替えられますが、 TRONコードの GB 2312 や KS X 1001 や JIS X 0212 は (単純なものとはいえ) いちいち計算しなければ対応関係がわかりません。
[591]
ゾーンが飛び飛びに配置されていることも面倒です。空きが有ることは構わないのですが、
符号平面を田の字型に4分割するゾーン設計のせいで、
符号を数値順にするとゾーンを行ったり来たりすることになります。
BTRONフォント形式が範囲内の符号の順にデータを並べるだけでも、
単なる「数値の両端の間」だけでない面倒な計算が入ってきています。
[593] 「JIS X 0208 の漢字全部」のような範囲を記述するのもなかなかに面倒です。
0x0000〜0x0020, 0x007F, 0x00A0:
制御コード (>>8)0x2121〜0xFDFD (抜けあり):
文字コード (>>10)0xFE21〜0xFE7E, 0xFE80〜0xFEFD, 0xFEFE:
言語指定コード0xFF21〜0xFF7E:
TRON仕様特殊コード0xFF80〜0xFFFE:
TRON仕様エスケープ0xFFFF: EOF[113]
個々の符号位置は 1-2121 のように面番号 (10進数) と2バイト分の値
(16進数4桁) で表記されるようです。
[234] ListAllTFont_20110126 - gtglyphlist.pdf, , https://charcenter.tron.org/tfont/repository/gtglyphlist.pdf
TC:FE222140
のような記述が使われています。 TC というのが TRONコードの略のようです。 面は言語指定コードを表す 0xFE 込みで表されています。
[8] 16ビットの面の 0x0000〜0x0020,
0x007F, 0x00A0
は制御コードとされ、次のものが定義されています。
| 符号位置 | 名前 | 説明 |
0x0000 | 無効 | 文字列終端。 |
0x0009 | タブ (HT, TAB) | 次のタブ位置またはフィールドへの遷移。タブ書式やフィールド書式が未設定なら無視。 |
0x000A | 改段落 (NL) | 改行または改段落。 |
0x000B | 改コラム | 改コラム。コラム指定されていないなら改ページと同じ。 |
0x000C | 改ページ | 改頁。図形内埋込み文章データなら改行と同じ。 |
0x000D | 改行 | フィールド内または段落内の改行。 |
0x0020 | セパレータ, プロポーショナルSP (英語モード) | 語や文節の区切れ。 |
0x00A0 | 英字固定ピッチSP (英語モード) |
以上の8つを使用し、残りの符号位置は使用しません BTRON3。
[343] 他のプラットフォームの改行コードに相当するものは 0x000A とされています。 >>342
1-2121 (JIS X 0208 和字間隔)1-222E (JIS X 0208 〓)... と変換するようです。 >>580
[342] Article, , https://web.archive.org/web/20031018081200/http://www.btron.com/cgi-local/tips/bbs.cgi?num=241&ope=v&page=0
[345] Article, , https://web.archive.org/web/20040228011513/http://www.btron.com/cgi-local/tips/bbs.cgi?num=242&ope=v&page=0
[14] TRON コードを設計した坂村健氏らは、 言語が異なれば文字も別に符号化した方がよいと考えていました。 また、 JIS の包摂規準や UCS の CJK統合漢字のように異なる字形を1つの符号位置にまとめるよりも、 できるだけ細かく分けて符号化して、 検索などで必要に応じて同一視するのが望ましいと考えていました。 その他色々な経緯から、既存の JIS の文字コードや UCS や大漢和辞典などの文字集合をそのまま取り入れたり、 独自に制作したGT書体の文字集合を取り入れたりしています。
[174] TRON (コード) の売りの1つは外字が必要ないこととされていましたが、 文字とそれ以外の敷居が低い TRON コード (TAD) では画像を文字とほとんど同じように扱えました。 ですから、 TRON コードには外字領域のようなものは用意されていません。
[175] 超漢字4 ユーザー専用FAQ集, , http://www.chokanji.com/support/ck4/ck4ans/char.html#Q757
必要な文字がシステムにない時に有効ですが、外字を使った文章はネットワークなどでやりとりすることができません。TRONでは難しい漢字や特殊な文字も扱えるようにTRONコードを用意しています。
「超漢字」では、このTRONコードを採用しているため、これまでに活字化された文字は網羅的に含まれています。そのため、外字を扱う領域はございません。
一方、文字ではなく何かのマークやロゴを文章に混ぜたい場合があると思います。そのようなときには、基本図形編集で作った図形を文章に埋め込んでください。埋め込み図形は、文字と同じようにレイアウト、印刷可能です。また埋め込み図形をいったん最小に変形すると、回りの文字サイズに合わせて大きさが自動で調節されます。
[256] TRON 側の Web 上の公式情報は多くが消えてなくなってしまっています。
[41] 第1編 共有データ 目次, , https://web.archive.org/web/20041031125545/http://www.personal-media.co.jp/tron/developer/doc/btron3/shared_data/index.html
[42] 第1編 BTRON3 仕様書に対する制限・補足, , https://web.archive.org/web/20041031151557/http://www.personal-media.co.jp/tron/developer/doc/brightv.r4/diff/index.html
[224] 超漢字ウェブサイト 更新履歴, , https://web.archive.org/web/20030604033134/http://www.chokanji.com/info/history.html
TRONプロジェクトはオープンポリシーを採っていますので、TRONコード仕様はオープンです。この仕様を下にプロダクト(ソフトウェア製品、フリーソフトウェア、フォントなど)を開発することはTRONプロジェクトに賛同されることにより自由です。またTRON文字収録センターはこれらのプロダクトの紹介など普及活動をいたします。
なお、TRON仕様の下に開発されたプロダクトは開発者の権利が発生しますのでそれらの利用については、使用条件の確認およびそれに基づく利用を行ってください。
[74] TRON文字収録センター, , https://web.archive.org/web/20110213052102/http://charcenter.t-engine.org/
[91] 文字セット改定のお知らせ, , https://web.archive.org/web/20100125035953/http://www2.tron.org/set.html
[157] 文字セット改定のお知らせ, , https://web.archive.org/web/20081204052024/http://www2.tron.org/set3.html
[84] 文字セット改定のお知らせ, , https://web.archive.org/web/20030808165241/http://www2.tron.org/set06.html
[83] 文字セット改定のお知らせ, , https://web.archive.org/web/20030808170239/http://www2.tron.org/set07.html
GB 18030 との対応
[95] 文字セット改定のお知らせ, , https://web.archive.org/web/20071226003334/http://www2.tron.org/set10.html
[96] 文字一覧, , https://web.archive.org/web/20080515073735/http://www2.tron.org/set10/hentai02.html
※9面8857のデザインが
〓 画像 (9面8521と同字形)になっていたので、本来の〓 画像 (ま:字母は「満」)に差し替えました。(2007年6月22日)
[89] TRONコード追加フォント(2001年7月), , https://web.archive.org/web/20030621173814/http://www.chokanji.com/download/font0107.html
※ 本書体データは、TRONWARE VOL.69(2001年5月31日発売)、およびVOL.70(2001年7月31日発売)に付属CD-ROMよりも新しいバージョンが収録されています。
特に、VOL.70付録の「陰陽五行」フォントには互換性の問題がございますので、必ずこちらのフォントをご利用ください。
[165] TRONコード追加フォント(2001年9月), , https://web.archive.org/web/20080725070926/http://www.chokanji.com/download/font0109.html
[16] TRONコードとは? - 超漢字ウェブサイト ( ( 版)) http://www.chokanji.com/ckv/manual/01-07-01.html
[17] TRONコード | 超漢字検索ウェブサイト ( (パーソナルメディア株式会社 著, 版)) http://www.chokanji.com/ckk/manual/troncode.html
[18] TRONコードとは? - 超漢字ウェブサイト ( ( 版)) http://www.chokanji.com/ckv/manual/01-07-01.html
[35] 超漢字V FAQ集 - 超漢字ウェブサイト, , http://www.chokanji.com/ckv/faqans/moji.html
[19] TRON文字収録センター ( ( 版)) http://charcenter.t-engine.org/
[311] 超漢字3の新機能・変更点, , https://www.chokanji.com/support/ck4/chokanjians/vupguider3.html
[310] 超漢字4の新機能・変更点, , https://www.chokanji.com/support/ck4/chokanjians/vupguider4.html
(書体, 文字検索の加除)
/SYS/USR/超漢字サンプル集/超漢字V収録文字リスト... に符号表があります。システムのフォントで表示されるもので、
初期状態では一部が欠けていますが、
該当フォントをインストールすると表示可能になります。
[646] 超漢字4 R4.100 バージョンアップ版, , https://web.archive.org/web/20030806101358/http://www.chokanji.com/download/ck4_100.html
- 「超漢字4 R4.100 フォント1 更新パッケージ」 13.6M
- 「超漢字4 R4.100 フォント2 更新パッケージ」 15.4M
- 「超漢字4 R4.100 フォント3 更新パッケージ」 11.4M
[647] >>646 このうち 1 は現存しません。 2, 3 は所蔵されています。
[650] 超漢字4 R4.100B バージョンアップ版, , https://web.archive.org/web/20040211095646/http://www.chokanji.com/download/ck4_100.html
- 「超漢字4 R4.100B 書体1 更新パッケージ」 13.6M 【R4.100B】
- 「超漢字4 R4.100B 書体2 更新パッケージ」 15.4M 【R4.100B】
- 「超漢字4 R4.100B 書体3 更新パッケージ」 14.2M 【R4.100B】
[648] 超�漢�字�4 R4.100B バ�ー�ジ�ョ�ン�ア�ッ�プ�版, , https://www.chokanji.com/download/ck4_100.html
- 2004年6月2日(水) R4.102公開にともない、不要な「書体1」のパッケージを削除。
- 2003年9月17日(水) R4.100B公開
- 2003年7月9日(水) R4.100公開
- 「�超�漢�字�4 R4.100B 書�体1 更�新�パ�ッ�ケ�ー�ジ�」�→R4.104で�の�書�体�の�更�新�パ�ッ�ケ�ー�ジ�を�ご�利�用�く�だ�さ�い�。
- 「�超�漢�字�4 R4.100B 書�体2 更�新�パ�ッ�ケ�ー�ジ�」 15.4MB【R4.100B】
- 「�超�漢�字�4 R4.100B 書�体3 更�新�パ�ッ�ケ�ー�ジ�」 14.2MB【R4.100B】
[649] >>648 このうち 1 は存在しません。 2, 3 は現存します。
[661] >>651 と >>649 で 2, 3 はフォントデータ自体は同じと推測されますが、 配布ファイルは変更されています。
[309] 超漢字4の R4.100、R4.100Bの変更点, , https://www.chokanji.com/support/ck4/chokanjians/vupguider41.html
- 書体実身(R4.100B)変更内容 [書庫 5KB] (2003年9月17日)
- 書体実身(R4.100)変更内容 [書庫:23KB] (2003年7月9日)
- TRONコードの改定やその対応方法に関する情報を含んでいます。改定についての詳細は、TRON文字収録センターをご覧ください。
[299] >>309 の2つ目 (R4.100) に記載されているのは、
[300] >>309 の1つ目 (R4.100B) はバランス調整が主ですが、 Unicode の字形修正がいくつか含まれます。
[669] 超漢字4 R4.102 バージョンアップ版, , https://web.archive.org/web/20040604084854/http://www.chokanji.com/download/ck4_102.html
- JIS範囲のコードをGT書体で表示すると、一部の字形が太くなる現象を修正。
- JIS第3・4水準、JIS補助漢字範囲のコードでもGT書体が利用できるように改良
[328] 詳細編:収録している文字の種類 | 超漢字検索ウェブサイト, パーソナルメディア株式会社, , https://www.chokanji.com/ckk/manual/charset.html
[329] TRONコード | 超漢字検索ウェブサイト, パーソナルメディア株式会社, , https://www.chokanji.com/ckk/manual/troncode.html
tron:fixedtron:removed[25] 第1面 (FE21) とりあえず多言語面 / システムスクリプト
[103] 超漢字になる前の製品は第1面だけで、「とりあえず」 中日韓が詰め込まれていたらしい。 >>22 (本来は言語指定コードによって言語が区別されるべきところ。)
[344] Article, , https://web.archive.org/web/20040309071305/http://www.btron.com/cgi-local/tips/bbs.cgi?num=345&ope=v&page=0
[167] JIS X 0208、JIS X 0213 第1面は GL と同じ。 >>55
[168] JIS X 0212 は GR + GL。 >>55 ただし Bゾーンは第1バイト 0xFE が範囲外なので、94区は表現できません。
[170] JIS X 0213 第2面は第1バイトが JIS X 0212 の手前に空き区を削って配置、 第2バイトは GL。 >>55
[208] 日本語EUCの JIS X 0213 対応拡張のように JIS X 0212 と JIS X 0213 第2面を重ね合わせればいいと思ってしまいますが、 TRONコードの構造上、 GR + GL の符号は94区が使えないので (>>207)、その方法だと JIS X 0213 の2面94区をどこかにずらして配置しなければなりません。 それをきらって全部他のところに詰め込んだのでしょうかね。
[620] >>55 に JIS X 0213 の面区点位置と TRONコードの変換の計算式の実装があります。
[114] JIS X 0213 は制定後に追加。元はただの JIS X 0208 のみ >>80。
[261] JIS X 0213:2004 改訂に追随していません >>260。
[262] 超漢字内の符号表では 「JIS第1・第2水準」 「JIS第3・第4水準」 「JIS補助漢字」 の3つになっていて、「JIS第3・第4水準」には JIS X 0208 部分が重出しています。 区と TRONコードの2バイト符号が表示されています。 >>258
[334] >>333 : JIS X 0213 への対応が追加された 超漢字2 の画面写真。
があります。説明を信じると、 >>647 で更新され、 それに続く >>651 >>649 では変更されていません。
があります。いずれも、 TrueType フォントが2つ含まれます。1つ目に対しては、 JIS X 0208 との対応が3つあります。 そのうちの2つは非漢字のそれぞれ一部で、 各々「比例」「縦書」とあります。 差分として使われるもののようです。 2つ目に対しても JIS X 0208 の「縦書」のグリフが数個あり、 改訂分を表していると思われます。
があります。 「比例」がないことを除いて >>419 と同じ構造です。
[497]
超漢字検索にはこれら4書体が同梱されており、
TrueType 部分は3つが同じですが、
SSゴシック (0002.dat)
は違うデータのようです。
があります。 TTC フォントと JIS X 0208 との対応が計4つあります。 2つは HG平成明朝体W3, 2つは HGP平成明朝体W3 とあります。それぞれ JIS X 0208 の全体と、 縦書の差分が1つずつあります。
があります。 TrueType フォントと、
の対応付けが含まれます。
があります。いずれも TrueType フォントと JIS X 0208 との対応があります。
があります。 JIS X 0208 のビットマップフォントが3種類、 その縦書差分が4種類入っています。
[485]
超漢字Vの内部の
/SYS/FONT/基本-明朝16
は、BTRON形式フォントファイルで、
JIS X 0208 (全角) と、
JIS X 0208 非漢字の3区まで (半角)
の2つのビットマップフォントが入っています。
[518] 超漢字Vの標準フォントの JIS X 0208 は JIS X 0208-1990 = JIS X 0208:1997 = JIS X 0213:2000 であり、 JIS X 0208-1983 に対する追加の2文字込みです。
[519] 超漢字Vの標準フォントの JIS X 0213 の13区は、 NEC特殊文字のうち JIS X 0208 と重複するため JIS X 0213 で予約とされている面区点位置については、字形を割り当てていません。 (従ってその部分について Windows標準キャラクターセットとの完全な互換性はありません。)
[486]
超漢字Vに標準添付されている
LXSS明朝体の基本非漢字-LXSS明朝体は、
BTRON形式フォントファイルで、
JIS X 0213 非漢字 (半角)
のビットマップフォントが入っいます。
[487]
超漢字Vに標準添付されている
ナガ10の基本-ナガ10は、
の3つのビットマップフォントがはいっています。 このうち半角は、 JIS X 0201 の8ビット符号に OEMコードページらしき CL 領域の字形を追加したものを、 BTRONフォント形式の機能で JIS X 0208 非漢字に対応付けています。
は、
の各2組のビットマップフォントを含みます。 >>493 は >>487 と同じ構造です。
基本-東雲まるもじ には1種2個、それ以外には3種6個のビットマップフォントが含まれます。
基本英数-SSCourier可変 (bold なし)基本英数-SSAvalon可変基本英数-SSEuromode可変基本英数-SSHelveticaN可変基本英数-SSHelvetica可変基本英数-SSTimes可変 (bold, italic)があります。 TrueType フォントと、 JIS X 0208 のうちASCII文字と同じまたは近いもの (すべてではない) との対応が入っています。 bold なしのものは1組。 注釈なしのものは2組で、うち1組は太字用。 bold, italic のものは太字とイタリックの組合せで4組。 いずれもグリフごとに前進幅が異なり、半角前後です。
があります。ビットマップフォントで、
が含まれています。
補助-SSゴシック可変 (非漢字・漢字)補助-明朝可変 (漢字)があり、 TrueType と JIS X 0212 が対応付けられています。
があります。 TrueType フォントが2つあり、1つ目と
との対応関係、2つ目と
との対応関係があります。また、縦書用として空のフォントデータレコードがあります。
[498] 超漢字検索には TrueType 部分がこれらと同じ SSゴシックとSS明朝が入っています。
があり、 JIS X 0212 漢字のビットマップフォントが入っています。
があり、 JIS X 0212 非漢字のビットマップフォントが5種と 「可変」の空のフォントデータレコードが1つあります。
[517] 超漢字Vの「文字検索」小物では、 JIS X 0208 と JIS X 0213 は日本基本と表示されます。 TRONコードと共に JIS の面区点位置が表示、指定できます。 第1面の JIS X 0208 文字は黒色、 JIS X 0213 文字は青色で区別されます。 第2面は JIS X 0213 ですが、すべて黒色です。
[520] 超漢字Vの「文字検索」小物では、 JIS X 0212 は日本補助と表示されます。 TRONコードと共に JIS の区点位置が表示、指定できます。
[604] BBB は ISO-2022-JP の JIS X 0208:1978, JIS X 0208:1983、 EUC-JP の JIS X 0208, Shift_JIS の JIS X 0208 のいずれも、 すべての区点位置をそのまま TRONコードの JIS X 0208 + JIS X 0213 第1面の部分に対応付けているようです。 >>580
[598]
BBB
は
EUC-JP の JIS X 0212
の93区までの区点位置をそのまま TRONコードの JIS X 0212
部分に対応付けているようです。
94区は JIS X 0208 の〓となります。
>>580
[336] Article, , https://web.archive.org/web/20040309071705/http://www.btron.com/cgi-local/tips/bbs.cgi?num=341&ope=v&page=0
[594] BBB の ASCII文字からの変換は、どの文字コードからでもほぼ同じで、 JIS X 0208 の非漢字の似た文字に対応付けられています。 >>580
0x20 1-2121 0x21 1-212A 0x22 1-2149 0x23 1-2174 0x24 1-2170 0x25 1-2173 0x26 1-2175 0x27 1-2147 0x28 1-214A 0x29 1-214B 0x2A 1-2176 0x2B 1-215C 0x2C 1-2124 0x2D 1-215D 0x2E 1-2125 0x2F 1-213F 0x30 1-2330 0x31 1-2331 0x32 1-2332 0x33 1-2333 0x34 1-2334 0x35 1-2335 0x36 1-2336 0x37 1-2337 0x38 1-2338 0x39 1-2339 0x3A 1-2127 0x3B 1-2128 0x3C 1-2163 0x3D 1-2161 0x3E 1-2164 0x3F 1-2129 0x40 1-2177 0x41 1-2341 0x42 1-2342 0x43 1-2343 0x44 1-2344 0x45 1-2345 0x46 1-2346 0x47 1-2347 0x48 1-2348 0x49 1-2349 0x4A 1-234A 0x4B 1-234B 0x4C 1-234C 0x4D 1-234D 0x4E 1-234E 0x4F 1-234F 0x50 1-2350 0x51 1-2351 0x52 1-2352 0x53 1-2353 0x54 1-2354 0x55 1-2355 0x56 1-2356 0x57 1-2357 0x58 1-2358 0x59 1-2359 0x5A 1-235A 0x5B 1-214E 0x5C 1-2140 0x5D 1-214F 0x5E 1-2130 0x5F 1-2132 0x60 1-212E 0x61 1-2361 0x62 1-2362 0x63 1-2363 0x64 1-2364 0x65 1-2365 0x66 1-2366 0x67 1-2367 0x68 1-2368 0x69 1-2369 0x6A 1-236A 0x6B 1-236B 0x6C 1-236C 0x6D 1-236D 0x6E 1-236E 0x6F 1-236F 0x70 1-2370 0x71 1-2371 0x72 1-2372 0x73 1-2373 0x74 1-2374 0x75 1-2375 0x76 1-2376 0x77 1-2377 0x78 1-2378 0x79 1-2379 0x7A 1-237A 0x7B 1-2150 0x7C 1-2143 0x7D 1-2151 0x7E 1-2131
[595] ただし、 Shift_JIS と ISO-2022-JP の JIS X 0201 では、
0x5C 1-216F
[596]
~ は文字コードに関わらず JIS X 0208 の¯に対応付けられています。
[600] BBB は Shift_JIS と EUC-JP の JIS X 0201 片仮名用図形文字集合の [ 0xA1, 0xDF ] を JIS X 0208 部分に対応付けているようです。 >>580
[601] EUC-JP の [ 0x8EE0, 0x8EFE ] の空きは適切に扱えないようです。 >>580
0x8EA1 1-2123 0x8EA2 1-2156 0x8EA3 1-2157 0x8EA4 1-2122 0x8EA5 1-2126 0x8EA6 1-2572 0x8EA7 1-2521 0x8EA8 1-2523 0x8EA9 1-2525 0x8EAA 1-2527 0x8EAB 1-2529 0x8EAC 1-2563 0x8EAD 1-2565 0x8EAE 1-2567 0x8EAF 1-2543 0x8EB0 1-213C 0x8EB1 1-2522 0x8EB2 1-2524 0x8EB3 1-2526 0x8EB4 1-2528 0x8EB5 1-252A 0x8EB6 1-252B 0x8EB7 1-252D 0x8EB8 1-252F 0x8EB9 1-2531 0x8EBA 1-2533 0x8EBB 1-2535 0x8EBC 1-2537 0x8EBD 1-2539 0x8EBE 1-253B 0x8EBF 1-253D 0x8EC0 1-253F 0x8EC1 1-2541 0x8EC2 1-2544 0x8EC3 1-2546 0x8EC4 1-2548 0x8EC5 1-254A 0x8EC6 1-254B 0x8EC7 1-254C 0x8EC8 1-254D 0x8EC9 1-254E 0x8ECA 1-254F 0x8ECB 1-2552 0x8ECC 1-2555 0x8ECD 1-2558 0x8ECE 1-255B 0x8ECF 1-255E 0x8ED0 1-255F 0x8ED1 1-2560 0x8ED2 1-2561 0x8ED3 1-2562 0x8ED4 1-2564 0x8ED5 1-2566 0x8ED6 1-2568 0x8ED7 1-2569 0x8ED8 1-256A 0x8ED9 1-256B 0x8EDA 1-256C 0x8EDB 1-256D 0x8EDC 1-256F 0x8EDD 1-2573 0x8EDE 1-212B 0x8EDF 1-212C
[169] GB 2312 はゾーンの先頭から942文字分に割り当てられている。 >>55 (第2バイトが GR よりも大きいので余計に入る。)
[531] 超漢字内の符号表では 「中国簡体字」 として区と TRONコードの2バイト符号が表示されています。 >>258
[313] >>299, >>311 : KS X 1001 フォントの修正
があって、それぞれ TrueType フォントとTRONコードの関係の記述があります。
[503] 超漢字検索には TrueType 部分がこれらと同じ SSゴシックとSS明朝が入っています。
があって、2つの GB 2312 ビットマップフォントと1つの「可変」とされた空のフォントデータレコードが含まれます。
[523] 超漢字Vの「文字検索」小物では、 GB 2312 は中国基本と表示されます。 TRONコードと共に GB の区点位置が表示、指定できます。
[599] BBB は EUC-CN の GB 2312 の区点位置をそのまま TRONコードの GB 2312 部分に対応付けているようです。 GBK 等の拡張には対応していないようです。 >>580
[341] Article, , https://web.archive.org/web/20040228012009/http://www.btron.com/cgi-local/tips/bbs.cgi?num=243&ope=v&page=0
[526] KS X 1001 はゾーンの先頭から942文字分に割り当てられている。 >>55 (第2バイトが GR よりも大きいので余計に入る。)
[268] 超漢字内の符号表では 「韓国漢字・ハングル」 として区と TRONコードの2バイト符号が表示されています。 >>258
があります。説明を信じると、 >>647 で更新され、 それに続く >>651 でも更新され、 その次の >>649 では変更されていません。
があって、それぞれ1つの TrueType フォントと TRONコードの関係が記述されています。
があって、2つの TrueType フォントと TRONコードの関係が記述されています。 2つ目はグリフが1つだけです。 >>313 の変更に対応すると思われます。
[504] 超漢字検索には TrueType 部分がこれらと同じ SSゴシックとSS明朝 (TrueType ファイル計3個) が入っています。
があって、2つのビットマップフォントが入っています。 また、「可変」というフォントデータレコードが2つ入っていますが、中身が空です。
[517] 超漢字Vの「文字検索」小物では、 KS X 1001 は韓国と表示されます。 TRONコードと共に KS の区点位置が表示、指定できます。
[605] BBB は EUC-KR の KS X 1001 の区点位置をそのまま TRONコードの KS X 1001 部分に対応付けているようです。 UHC 等の拡張には対応していないようです。 >>580
[346] Article, , https://web.archive.org/web/20040228010309/http://www.btron.com/cgi-local/tips/bbs.cgi?num=245&ope=v&page=0
[219] ハングル hanguloj, Simatani takesi, https://esperanto.sannasubi.com/hangulo.htm
テキスト形式TRONコードでハングルを書いた例。
[115] 点字は「TRONイネーブルウェア」とだけ説明された独自仕様 >>80, >>81。
[274]
超漢字V
の符号表
には
「-で表したもの。
>>258
があります。 TrueType フォントと TRONコードとの対応関係があります。
があります。 六点点字と八点点字のビットマップフォント計2つが含まれます。
[444]
「表示用」「固定」は点なしを - で表しています。
「印刷用」は点のみで、点なしは無記号です。
点の位置は同じです。
[512] 超漢字検索には TrueType 部分が「表示用」と同じフォントが入っています。
[546] 超漢字Vの「文字検索」小物では、 「その他」の「六点点字」「八点点字」に属し六点点字または八点点字と表示されます。 TRONコードと共に区点位置が表示、指定できます。
[547] 六点点字は、1区の1点から64点とされています。
[548] 八点点字は、1区1点から2区94点までと3区1点から3区68点とされています。
[621]
六点点字は、 Unicode の U+2800 からの並び順と同じです。
ただし Unicode は六点点字と八点点字を統合しており、
代表字形は八点点字です。そのうち上6点に当たります。
[622]
八点点字は、 Unicode の U+2800 からと集合としては同じですが、
並び順が違います。 Unicode は六点点字相当を先に並べているのに対し、
TRON では完全に規則的です。
tron:definitionss:glyph-sharedgt:glyph-sharedt:glyph-shared[249] wenjian, , https://www.eonet.ne.jp/~kenn/wenjian.html
[250] >>249 Unicode の漢字とテキスト形式TRONコードの変換表。 第1面から第6面あたりが使われている模様。
wenjian:JIS3・4→各国wenjian:台湾→各国wenjian:CJK互換→日本基本・補助wenjian:各国→JIS3・4wenjian:IBM2TRONwenjian:Uni2Tronwenjian:UniGokanwenjian:日本基本補助→中国基本wenjian:各国漢字→旧字体wenjian:日本基本補助→旧字体wenjian:旧字体文書→Uni[353]
TRONコードの第2面 (言語コード 0xFE 0x22) と第3面
(言語コード 0xFE 0x23) には
GT 書体が割当てられています BRV。
[26] 第2面 (FE22)、第3面 (FE23)、第4面 (FE24) GT書体 >>35
[117] 何度かに分けて追加、重複削除されている。
[152] >>82, >>93, >>299 重複削除, GT番号一覧あり
GT67548-GT69263の範囲の追加(3字欠番)
収録コード範囲 3面Bゾーン ed62-fd7e, 3面Cゾーン 2180-22b8
文字数 1713
2-2121〜2-FDFD
GT書体フォント2000 (GT00001〜GT48400)
BRV (超漢字3以降)3-2121〜3-E54B
GT書体フォント2000 (GT48401〜GT66773)
BRV (超漢字3以降)3-E54C〜3-ED65
GT2000書体 Ver.2.20 GT66774〜GT67551) (773文字) 2001/09/14GT66774〜GT67547) (欠番1つ) BRV3-ED66〜3-FDFD 予約 BRV[360] グループ:GTコード - GlyphWiki, https://glyphwiki.org/wiki/Group:GT%E3%82%B3%E3%83%BC%E3%83%89
[361] グループ-ノート:GTコード - GlyphWiki, https://glyphwiki.org/wiki/Group-talk:GT%e3%82%b3%e3%83%bc%e3%83%89
[362] オープンギャラリー:超漢字2用GT書体, , http://www.ne.jp/asahi/open/gallery/trial/gtfont/gtfont.htm
[116] GT書体フォントが割り当てられているが、 Tフォントも使えるらしい。
[128] 書体関連や TRONコード以外の実装、 GT書体部分を中心とした実装などについては、 GT書体を参照。
[263] 超漢字Vの符号表は、 「GT書体フォント」 として GT の十進数の番号だけが示されています。 1 から 78774 まであります。 >>258
[655] >>647 の 1 は現存しませんが、 GT書体が含まれていたと推測されます。
があります。
[656] >>652 は >>655 の改訂版です。変更の詳細は >>655 が現存しないため不明ですが、 説明を見る限り、字形以外の修正です。
があります。 説明によると JIS X 0213 との対応はこの版で追加されています。
があります。
があります。
[370] >>364 は、 GT書体の TrueType フォント多数のそれぞれに対して、 フォントデータレコードが複数あり、 TRONコードの
への対応表が入っています。
[375] また、縦書き用のフォントデータレコードも入っていますが、 空です。縦書きに対応できるが字形差分なしということなのでしょうか。
[376] >>365 は、 GT書体の TrueType フォント3つに対して、
への対応表が入っています。
[382] >>366 は、 Tフォントの TrueType フォント多数に対して、
への対応表が入っています。
[625] これらの対応表によって記述された GT書体/Tフォントと JIS との対応関係を比較すると、 Tフォントの3つは同じですが、 GT書体 (追加含む。) にはなかった
が増えています。
[515] 超漢字検索にはこれら GT書体, Tフォントの計4種類の書体が収録されています。 TrueType データは 超漢字V のものや Web で配布されている BTRON形式フォントと一部異なっているものがあるようです (詳細不明)。
[521] 超漢字Vの「文字検索」小物では、 2面と3面が GT と表示されます。 TRONコードと共に GT 番号が表示、指定できます。
[298] 超�漢�字�4 R4.200 機�能�強�化�の�詳�細�内�容, , https://www.chokanji.com/support/ck4/chokanjians/vupguider42.html
[320] 超漢字3 ユーザー専用FAQ集, , https://www.chokanji.com/support/ck4/ck3ans/ckkojien.html
これらの文字については、書籍版「広辞苑」の印刷書体はGT書体フォントの文字になっており、「超漢字広辞苑」においてもこれらの文字を採用しています。
[574] オープンギャラリー:超漢字2用GT書体, , https://www.os-museum.com/trial/gtfont/gtfont.htm
[180] 未使用
[125] 「Big5(CNS 11643-1986)」と説明されている。 >>80, >>81
[126] Big5 の重複漢字2文字はどうなっているのか?
[36] 第7面 (FE27) 中国語伝統字に予約 >>35
TRONコードの概要では CNS 11643-1986 となっているが、超漢字の文字検索小物のコード表やB-right/Vの仕様では第三字面以降の対照も確認できるため、第七字面まで拡張された 1992 版と判断した
[171] 第6面から第7面にまたがって、 CNS 11643 の第1字面1区1点から第7字面94区94点まで先頭から順に詰め込まれている。 >>55
[272] 超漢字の符号表には 「中国伝統字」 として CNS 11643 の第1字面と第2字面が示されており、 面区点位置が記載されています。 >>258
があります。説明を信じると、 >>647 で更新され、 それに続く >>651 でも更新され、 その次の >>649 では変更されていません。
があります。 TrueType フォントが3個あります。6面の大部分が1つ目に、 飛び飛びの数個が2つ目に、 制御文字の略号の文字が3つ目に関連付けられています。
[434] >>431 の区分は改訂履歴と関係していると思われます。
[506] 超漢字検索には TrueType 部分がこれらと同じ SSゴシックとSS明朝が入っています。
[532] 超漢字Vの「文字検索」小物では、 CNS 11643 は台湾と表示されます。 TRONコードと共に CNS の面区点位置が表示、指定できます。
[533] 標準フォントは1面と2面しかありませんが、「文字検索」では7面まで存在しています。
[619] BBB の Big5 は [ 0xA140, 0xF8FE ] と [ 0xF940, 0xF9D5 ] を6面に対応させています。 Big5 と CNS 11643 の関係と同様、ほぼ規則的ですが、 たまに対応関係が乱れます。 なお [ 0x81, 0xA0 ] は第1バイト扱いになりません。 >>580
[707] BBB の Big5 は普通の版ではなく、 Unicode Consortium 版かもしれません。
[11] 大漢和辞典収録文字 (FE28, FE29)、記号類 (FE29)
[119] 第9面の残りはWebサイトで順次追加されフォントが配布されていた。
[564] どうせ面には余裕があるのになぜ9面に詰め込んだのかが謎です。 大漢和辞典は増えないだろうから空きがもったいないということなのでしょうが...
8-2121〜8-FDFD 大漢和辞典修訂二版 00001〜48055 [C3] [BRV] 9-2121〜9-353A 大漢和辞典修訂二版 48056〜49964 [C3] [BRV] 9-353B〜9-3D6E 大漢和辞典修訂二版補巻001〜804 [C3] [BRV] 9-3D6F〜9-7E7E reserved [BRV]
[118] 今昔文字鏡が削除されて代わりに追加されたらしい。 (文字鏡番号の最初の方は大漢和辞典番号と同じ。 しかしTRONコードでの割当位置はまったく別。)
[209]
TRONコードの大漢和辞典は欠番を詰め、ダッシュ、二重ダッシュを挿入して並べているので、
大漢和辞典の番号と簡単な計算でTRONコードを得られないらしいです。
の2つがあります。 >>258
があります。
があります。
[660] 説明を信じれば、 >>658 と >>655 で字形自体の変更はありません。 >>655 の2つは配布ファイルが違いますが、フォントデータには変更がありません。
があります。 TrueType フォントが2つはいっています。
[436] うち1つ目は、
との対応関係があります。
[437] 2つ目は、8面、9面のいくつかと対応付けられています。 >>307 の改訂と関係あると思われます。
[438] 他に縦書用として空のフォントデータレコードが2つあります。
[499] 超漢字検索には8面、9面についてこれらと同じ TrueType データの書体が同梱されています。
[522] 超漢字Vの「文字検索」小物では、 大漢和と表示されます。 TRONコードと共に大漢和辞典の番号が表示、指定できます。 「本巻」または「補巻」の番号で、ダッシュ付きも含まれます。
利用事例
[155] >>95 でに追加、 公表後に変体仮名の表2でに1文字訂正あり (文字表は Internet Archive 所蔵なし)
[275]
超漢字V
の符号表
には
「
に分かれています。 >>258
[277] >>275 のうち濁点仮名と住基仮名には、 現在TRONプロジェクトから書体が未提供で、 提供され次第超漢字の公式サイト http://www.chokanji.com/support.html で案内すると記載があります。 初期状態では字形が表示されません。
[278] 当該サイトには、ここで参照されているものであるとの説明は一切ありませんが、 「Tフォント」のダウンロード案内が記載されています。 指示に従ってTフォントをインストールすると、 符号表に字形が表示されるようになります。
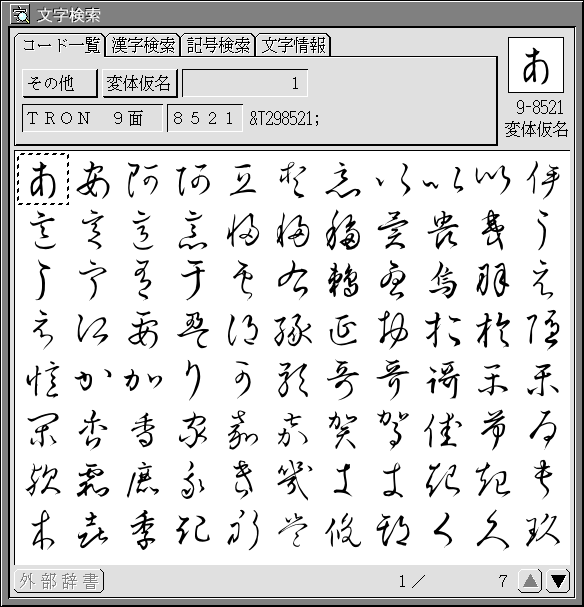
[286] 超漢字Vの「超漢字サンプル集」→「多漢字・多文字の世界」→ 「ユーザ辞書」→「変体仮名変換辞書」 に現代仮名1,2文字から変体仮名等への辞書があります。 変換先はすべて 9-8521 からの領域の文字です。
[296]
超漢字V
の
「超漢字サンプル集」→「多漢字・多文字の世界」→「変体仮名一覧」
に
1
番から
545
番まで字母 (字源の漢字, 複数個あるものもあり)、
読み (複数個の読みがあるものや読みが複数のものもあり)、
属性 (ひらがな、ひらがな合字、
[292]
超漢字V
の
「超漢字サンプル集」→「多漢字・多文字の世界」→「伊勢物語」
に
伊勢物語冒頭を右上縦書きで変体仮名を使って表示した例文があります。
「
[293]
「変体仮名」とはいっていますが、現行仮名に近い字形も入っているので、
すべて「変体仮名」フォントで統一されています。その中に1文字だけ「
[294] それでも「固定ピッチ」は現代の電子文書の変体仮名の崩し気味の書体ならこうなるだろうという仕上がりになっています。
[295] それに対して「比例ピッチ」はかなり醜い。正方形基本の現代的な字形はそのままに、 上下のアキを詰めて無理矢理連綿ぽく見せています。部分的にはそれっぽい表示になっているところもあるものの、 全体的にみるとかなり不自然で、上下の文字が (連綿でもない) 重なりに近い状態になっている箇所もあります。 古文書どころか(現代)書道の経験もない人が想像で作った前近代風文章、というイメージです。
があります。 TrueType フォントが4つ含まれ、
9-8021 - 9-846A9-8021 - 9-846A 「比例」9-8021 - 9-846A 縦書用 (差分だけでは無い)9-8021 - 9-846A 縦書用 (差分だけでは無い)「比例」と対応付けられてます。4つの TrueType は文字幅と書字方向に対応するようです。
ただし
非漢字-T楷書可変
はかわりに2つの TTC となっています。
[516] 超漢字検索にも収録されています (>>515)。
があります。 TrueType フォントが4つあり、
と対応付けられています。1つめと通常と縦書 (差分だけでは無い)、 2つめと縦書「比例」が対応付けられています。 また、1字の変更分について3つめと通常・縦書、4つめと縦書「比例」が対応付けられています。
[513] 超漢字検索には TrueType 部分がこれら4つと同じフォントが入っています。
[559] 超漢字Vの「文字検索」小物では、 「その他」の「濁点仮名」「住基仮名」「変体仮名」に属し濁点仮名, 住基仮名, 変体仮名と表示されます。 TRONコードと共に十進数が表示、指定できます。
の範囲です。
[189] 「あ゛」「え゛」も表示――12万字のフォント無償公開 - ITmedia NEWS, https://www.itmedia.co.jp/news/articles/0512/15/news084.html
[33] グループ:TRONコード濁点付きひらがな・カタカナ - GlyphWiki ( 版) http://glyphwiki.org/wiki/Group:TRON%E3%82%B3%E3%83%BC%E3%83%89%E6%BF%81%E7%82%B9%E4%BB%98%E3%81%8D%E3%81%B2%E3%82%89%E3%81%8C%E3%81%AA%E3%83%BB%E3%82%AB%E3%82%BF%E3%82%AB%E3%83%8A
[211] GlyphWiki には字形があっても >>33 の表に載ってないものが多い。
[212] >>211 GlyphWiki の dump を使えば他の文字も Unicode との対応関係を取得できます。
[130] 変体仮名は今昔文字鏡にもあったがまったく異なる集合。
[59] グループ-ノート:TRONコード住民基本台帳収録変体仮名 - GlyphWiki, https://glyphwiki.org/wiki/Group-talk:TRON%E3%82%B3%E3%83%BC%E3%83%89%E4%BD%8F%E6%B0%91%E5%9F%BA%E6%9C%AC%E5%8F%B0%E5%B8%B3%E5%8F%8E%E9%8C%B2%E5%A4%89%E4%BD%93%E4%BB%AE%E5%90%8D
[78] グループ:tsuruki-work-test - GlyphWiki, https://glyphwiki.org/wiki/Group:tsuruki-work-test
TRONコード含む各種変体仮名の対応関係 (TRONコードは住基部分のみ)
[53] 住民基本台帳収録変体仮名 - Wikipedia, , https://ja.wikipedia.org/wiki/%E4%BD%8F%E6%B0%91%E5%9F%BA%E6%9C%AC%E5%8F%B0%E5%B8%B3%E5%8F%8E%E9%8C%B2%E5%A4%89%E4%BD%93%E4%BB%AE%E5%90%8D
符号表 (文字画像)
[185] Juki-Gana - Wikimedia Commons, , https://commons.wikimedia.org/wiki/Juki-Gana
符号表 (文字画像)
[217] 変体仮名(超漢字Vのフォントが必要), Simatani takesi, https://esperanto.sannasubi.com/hentai.htm
[218] >>217 独自変体仮名の字母対応表 (Shift_JIS + テキスト形式TRONコード)
全部が掲載されてるわけではない。
[239] GlyphWiki やにしき的フォントの字形がどの程度超漢字のフォントの字形を再現しているのかは不明です。 また、超漢字のフォントがどの程度住基文字の字形を再現しているのかは不明です。
[151] >>82, >>299 「修正」、新旧対応表と変更後の文字表あり
「超漢字3」「超漢字4」用のiモード絵文字フォント(拡張)は、パーソナルメディア発行のTRONWARE Vol.76 附録CD-ROMに収録されています。またパーソナルメディアのサイトのここからダウンロードできます。
[2] iモード絵文字で間違いの修正と称して非互換変更が行われたようです。使ってた人は困ってるみたい。文字コードの連中は懲りないなあ。
追加i-mode絵文字のうち、9-922B~9-9247の29文字のコードポイントが、NTT-Docomoが公開している仕様とずれていた問題に対応しました。
(「文字検索」の仕様変更の告知。文字情報が古いままだったということ?)
[273] 超漢字V の符号表 には 「iモード絵文字」 としてTRONコードの面と2バイト符号の表があります。 >>258
[572] >>88 にも同様の符号表があります。 >>88 はフォントの修正前のものですが、 符号表自体は文字データなので、同等のものと思われます。
[573] >>88 には文字の簡単な説明の表があります。修正前のものです。 iモード絵文字の [ 167, 196 ] と [ 拡1, 拡76 ] の計106個が対象です。 (このうち前半の196までが >>178 です。)
[643]
この番号のうち、 [ 167, 175 ] はドコモの資料の番号と一致します。
177 = 9-9234 (旧) は、ドコモの資料の 176 番と一致します。
[ 178, 196 ]
は、
ドコモの資料に出現しないものの端末に実装されている絵文字です。
が入っています。拡張前の初期版と思われます。ただし、 >>89 は字形以外の部分に修正が入った更新と説明があります。通算2代目でしょうか。
があります。これは拡張後、修正前のものです。通算3代目でしょうか。
があります。説明を信じると、 >>647 で更新され、 それに続く >>651 >>649 では変更されていません。 >>647, >>649 とも修正後のものです。
があります。これは拡張後、修正後のものです。通算4代目でしょうか。
[629] >>395 は
TrueType フォントで、 9-2121 - 9-937E
と対応付けられています。
名前が「可変」となっていますが、どの字形も全角です。
[509] 超漢字検索には TrueType 部分がこれと同じフォントが入っています。
[534] 超漢字Vの「文字検索」小物では、 「その他」の「iモード」に属しiモードと表示されます。 TRONコードと共にシフトJISの十進数5桁 [ 63647, 63996 ] が表示、指定できます。
[616] BBB の Shift_JIS は、 標準では [ 0xF0, 0xFC ] を第1バイトではなく未知のバイトとみなします。 >>580
[617]
BBB の Shift_JIS でiモード絵文字を有効にすると、
[ 0xF89F, 0xF9FC ]
が2バイト文字として認識され、
[ 9-9121, 9-937E ]
に順に対応させられます。
>>580
[65] iモード絵文字 - Wikipedia, , https://ja.wikipedia.org/wiki/I%E3%83%A2%E3%83%BC%E3%83%89%E7%B5%B5%E6%96%87%E5%AD%97#TRON%E3%82%B3%E3%83%BC%E3%83%89
[182] I-mode Character - Wikimedia Commons, , https://commons.wikimedia.org/wiki/I-mode_Character
[222] 9-944F 9-9451 9-9475 が未割当。
[146] >>91 で追加、ただし文字表は Internet Archive 未所蔵
[631] TRONWARE Vol.98 にフォントが付属したそうです。
があります。 >>631 の後に字形以外の修正が入ったものと説明があります。
があります。 TrueType フォントで、 9-9421 - 9-955F
に関連付けられています。字形に合わせて前進幅が異なり、
全角より狭いものも少なくありません。
[511] 超漢字検索には TrueType 部分がこれと同じフォントが入っています。
[549] 超漢字Vの「文字検索」小物では、 「その他」の「ホツマ」に属しホツマと表示されます。 TRONコードと共に十進数が表示、指定できます。
[550]
十進数は単純な連番のようで、空き領域も含めて 1 - 188 (= 9-957E)
の範囲です。
[193] ホツマ文字サンプルデータ集 - 超漢字ウェブサイト, , http://www.chokanji.com/ckv/hotsumasample.html
[197] ホツマ文字用世界文字入力追加モジュール - 超漢字ウェブサイト, , http://www.chokanji.com/ckv/hotsuma.html
[637] >>197 は >>89 にも付属します。同じものか古い版かは不明。
[397] >>197 を使うと仮名のようにローマ字入力でホツマ文字を入力できます。 (かな入力方式もあるのかは未確認。) 現在の一般的な仮名のローマ字入力では入力途中の子音字がラテン文字で表示されるのに対して、 この入力システムではホツマ文字の文字素が表示されます。
[196] TRONWARE VOL.69 正誤表 - パーソナルメディア書籍サイト, , https://www.personal-media.co.jp/book/seigo/seigo_182.html
TRONWARE VOL.69のCD-ROMに収録されている「TRONコード追加フォント」内のホツマ文字セットに関する資料の中で以下の誤りがありました。
- 文字コード一覧表に3箇所誤りがあった。
- ヲシデ一覧で異体の情報に1箇所誤りがあった。
修正版をダウンロードしてご利用ください。
※書体(フォント)データそのものや、世界文字入力モジュールには誤りはありません。
文字コード一覧
9‐9559〜9−955bま での文字が重複していたのを修正しました。
ヲシデ一覧
「
〓 ホツマ文字 9-953F 」を「ナ」の異体と表記 していたのを、「ヌ」の異体に修正しました。
[246] >>196 配布ファイルにはホツマ文字の説明が入っています。 表計算形式で、文字とそれに対応する仮名等が書かれています。
[247] >>246 のうちホツマ文字の異体字についての部分より。
” 27 95” ” 28 95” ” 29 95” ” 2A 95” ” 2B 95” ” 2C 95” ” 2D 95” ” 2E 95” ” 54 95” ” 55 95” ” 56 95” ” 57 95” ”あ” ”い” ”う” ”こ” ”が” ”ぎ” ”ぐ” ”げ” ” 58 95” ” 2F 95” ” 30 95” ” 31 95” ” 59 95” ” 5A 95” ” 5B 95” ” 32 95” ” 33 95” ” 34 95” ” 35 95” ” 36 95” ”ご” ”は” ”ば” ”ひ” ” 37 95” ” 5C 95” ” 5D 95” ” 38 95” ” 39 95” ” 3A 95” ” 5E 95” ” 3B 95” ” 3C 95” ” 3D 95” ” 3E 95” ” 3F 95” ”ひ” ”び” ”ふ” ”ぶ” ”ほ” ”な” ”ぬ” ” 40 95” ” 41 95” ” 42 95” ” 43 95” ” 44 95” ” 45 95” ” 46 95” ” 47 95” ” 48 95” ” 5F 95” ” 49 95” ” 4A 95” ”め” ”も” ”た” ”ち” ”る” ”ろ” ”す” ”ぞ” ”よ” ”わ” ” 4B 95” ” 4C 95” ” 4D 95” ” 4E 95” ” 4F 95” ” 50 95” ” 51 95” ”を”
27 95 は 9-9527 を表します。文字の下の仮名が対応関係にあるものです。 仮名空欄はその左側と同じことを表します。
tron:ホツマ:行tron:ホツマ:段[194] 超漢字、幻の神代文字「ホツマ文字」をサポート | スラド, https://srad.jp/story/01/07/29/0228206/
[632] 陰陽五行は「いんようごぎょう」と振り仮名があります。 >>89
[633] 八卦占いや陰陽道のシンボルを集めたとのことです。 >>89
[223] 9-9621 は空白? 未割当? 字数が86文字だから未割当ぽい。
[156] >>89 初期に配布されたフォントは正式仕様と違うらしい。
[316] TRONWARE VOL.70 正誤表 - パーソナルメディア書籍サイト, , https://www.personal-media.co.jp/book/seigo/seigo_185.html
本誌付録CD-ROM内の「TRONコード最新フォント」に収録されている「陰陽五行シンボル」のフォントデータには、前号VOL.69収録の同フォントデータとの互換性の問題がございます。「超漢字」には登録しないようお願いいたします。
[673] Web 上で配布されたものはすべて修正後のもののようです。 修正前の状態については資料も見当たりません。
[198] 陰陽五行文字, , https://web.archive.org/web/20010622071215/http://www2.tron.org/set/h0.html
があります。 >>316 の修正後のものです。
があります。 TrueType フォントが2つあります。1つは通常、もう1つはボールドで、
9-9622 - 9-9677
に対応付けられています。
「可変」という名前ですが、すべて全角の字形です。
[399] ボールドは、通常と比べると墨の部分が一回り大きくなっていますが、 単純な機械的拡大ではなく若干の調整が入っているようです。 六十四卦等と違って八卦以下は、通常に比べて太字版がかなり大きく拡大されます。
[636] 「より見やすい文章のため」に意図的に太字書体を追加したと説明があります。 >>89
[510] 超漢字検索には TrueType 部分がこの通常版と同じフォントが入っています。
[551] 超漢字Vの「文字検索」小物では、 「その他」の「陰陽五行」に属し陰陽五行と表示されます。 TRONコードと共に十進数が表示、指定できます。
[158] >>157 追加 (文字表 Internet Archive 所蔵なし)
[640] >>165 に符号表があります。付属のフォントを使った表示が想定されるものです。
[221] 収録文字は符号位置順に、 □ 一 - 十, () ア - モヤユヨラリルレロワヰヲン, ○ i - iv - ix x xi xii, △ 1 - 20
があります。 TrueType フォントです。
があります。 TrueType フォントで、
9-9721 - 9-977A
に対応付けられています。
[508] 超漢字検索には TrueType 部分がこれと同じフォントが入っています。
[553] 超漢字Vの「文字検索」小物では、 「その他」の「序数」に属し序数と表示されます。 TRONコードと共に十進数が表示、指定できます。
[554]
十進数は単純な連番のようで、空き領域も含めて 1 - 94 (= 9-977E)
の範囲です。
[642] b_freesoft, , https://www.eonet.ne.jp/~nisaka/b_freesoft.html
序数記号辞書R2.01 [2001/10/08(月)](「超漢字4」に収録)
概要:超漢字で使える丸付きや括弧付き、枠付きの数字(アルファベット・カタカナ、ローマ数字なども含む)や上付き、下付き数字などの序数記号の辞書(例えば、こんな記号)です。
[71] グループ:TRONコード序数記号 - GlyphWiki, https://glyphwiki.org/wiki/Group:TRON%e3%82%b3%e3%83%bc%e3%83%89%e5%ba%8f%e6%95%b0%e8%a8%98%e5%8f%b7
[213] GlyphWiki の dump を使えば Unicode文字列または Adobe-Japan1 の同字形との対応表を抽出できます。それでも一部はTRONコード独自です。
[641]
>>71 は先頭10文字を□囲みとしていますが、
>>565 の字形は ■ の中に角丸の白四角を入れたような形で囲んでいます。
TRONコードに字形以外の説明がないため、意図は不明です。
一部のみ TRONコードを出典に PUA に採録、互換性はなし。
[238] GlyphWiki やにしき的フォントとかつて公式サイトで公表されていた例示字形は、 一般的に無視される程度の字形差があります。
[276] 超漢字V にはフォントが標準で付属しますが、なぜか初期状態で無効になっています。 符号表では字形が表示されませんが、 登録方法の案内があります (>>275)。 それに従って操作すると表示されるようになります。
[391] >>276 は ath-Koganei可変 というBTRONフォント形式のフォントで、
ASCII文字を置き換えた TrueType フォントを含み、
それと TRONコードとの対応を記述した形になっています。
[394] >>393 で配布されている BTRONフォント形式のフォントは >>276 と同じものと思われます。
[388] >>85 の字形は >>276 のフォントのものと思われます。
[390] >>85 の公式の符号表や >>276 のフォントデータレコードには
9-9821
に空白が入っています。 >>186 >>52 の符号表ではこれが欠落していますが、
>>186 >>52 制作者の見落としと思われます。
[557] 超漢字Vの「文字検索」小物では、 「その他」の「アーヴ」に属しアーヴと表示されます。 TRONコードと共に十進数が表示、指定できます。
[558]
十進数は単純な連番のようで、空き領域も含めて 1 - 94 (= 9-987E)
の範囲です。
[392] 超漢字V FAQ集 - 超漢字ウェブサイト, , https://www.chokanji.com/ckv/faqans/moji.html#Q430
[674] ath_font.pdf, , https://tad-wg.jp/spec/ath_font.pdf
[675] Athdoc_bpk.pdf, , https://tad-wg.jp/sample/Athdoc_bpk.pdf
[199] >>54 にTRON側に提出したというフォントのリンクがある (リンク切れ、 Internet Archive にも所蔵なし)。 超漢字が搭載していたという 「フリーフォント」 >>275 か?
[52] アース (文字) - Wikipedia, , https://ja.wikipedia.org/wiki/%E3%82%A2%E3%83%BC%E3%82%B9_(%E6%96%87%E5%AD%97)
[186] Baronh - Wikimedia Commons, , https://commons.wikimedia.org/wiki/Baronh
符号表 (画像)
[28] 中国伝承文字、少数民族文字類 (FD10)
10-2121〜10-2F7E トンパ文字 (1362) [2001/05/24] [BRV] 10-3021〜10-FDFD reserved [BRV]
[184] >>91 で追加、文字表は一部のみ Internet Archive 所蔵
[120] トンパ文字のフォントは超漢字4と別製品で売られていました。
[279] 超漢字Vではトンパ文字のフォントが標準搭載されています。 関係するドキュメントもいくつか最初から入っています。
[280] 超漢字4版の Webサイトで無償配布されていたトンパ文字関係のドキュメントは 超漢字Vに入っていないようですが、手動でダウンロードして追加できます。
[281]
超漢字V
の符号表
には
「
[285] 超漢字V の 「超漢字サンプル集」→「多漢字・多文字の世界」→「ユーザ辞書」→「トンパ辞書」 に仮名漢字変換の辞書があります。 名詞、動詞、形容詞などの日本語への意訳の他に、 仮名1文字に対応する音訳字や日本の主要地名の音訳らしき文字列も入っています。
[287] 超漢字V の 「超漢字サンプル集」→「多漢字・多文字の世界」→「トンパDB」 に文字と簡単な意味説明が 1 番から 1362 番まであります。また、1つ上の階層にはトンパ文字の例文などがいくつかあります。
があります。 TrueType フォントと
10-2121 - 10-2F4E
との対応があります。
[514] 超漢字検索には TrueType 部分がこれと同じフォントが入っています。
[555] 超漢字Vの「文字検索」小物では、 「その他」の「トンパ」に属しトンパと表示されます。 TRONコードと共に十進数が表示、指定できます。
[556]
十進数は単純な連番のようで、空き領域も含めて 1 - 1410 (= 10-2F7E)
の範囲です。
[183] Tomba Script Character - Wikimedia Commons, , https://commons.wikimedia.org/wiki/Tomba_Script_Character
符号表、ごく一部
[63] トンパ文字 - Wikipedia, , https://ja.wikipedia.org/wiki/%E3%83%88%E3%83%B3%E3%83%91%E6%96%87%E5%AD%97
[166] 「超漢字トンパ書体」サンプルデータ集, , https://web.archive.org/web/20090504034437/http://www.chokanji.com/download/cktompasample.html
[121] 超漢字の一時期に今昔文字鏡が割り当てられていた。
ライセンス問題で実装不可能な要件を提示されたので存在が抹消されたとか。
[123] 第11面は大漢和辞典 + 今昔文字鏡 (大漢和辞典を除く) と説明されていた。 >>80 ところが大漢和辞典部分もまとめてなかったことに。 >>81 (大漢和辞典部分も文字鏡フォントで実装されていたから?)
[243] 実際に使われていたのは11面から13面まで。 14面と15面はそれのために予約とされていた。
[131] 今昔文字鏡非漢字のうち、 甲骨文字、 水文、 梵字はかわりになるものがその後追加されていない。
[220] 変体仮名(超漢字2の文字鏡フォントが必要), Simatani takesi, https://esperanto.sannasubi.com/hentai2.htm
テキスト形式TRONコードによる変体仮名と字母との対応表。
[335] Article, , https://web.archive.org/web/20030909063642/http://www.btron.com/cgi-local/tips/bbs.cgi?num=239&ope=v&page=0
[338] Article, , https://web.archive.org/web/20040305065309/http://www.btron.com/cgi-local/tips/bbs.cgi?num=303&ope=v&page=0
[339] Article, , https://web.archive.org/web/20040228011151/http://www.btron.com/cgi-local/tips/bbs.cgi?num=246&ope=v&page=0
[708] XユーザーのTsukasa #01さん: 「超漢字: 初版をブート。 文字検索ウィンドウと今昔文字鏡文字テーブルを見せた状態まで。 https://t.co/mzbki98O11」 / X, , https://x.com/a4lg/status/1841627759254397056/photo/3
[30] 第16面、第17面 Unicode (漢字、ハングルを除く BMP) >>22
[132] Unicode 2.0 当時のもの。 >>80, >>81
[133] ハングル音節が除外されているが、 KS X 1001 分しか TRONコードには他にない。 重複でもどんどん追加していく方針だった TRONコードがなぜ 漢字とハングルはここで省いたのか謎。 (GT書体と重複するはずの大漢和辞典をわざわざ用意しているから、 フォントの調達が大変とかそういう問題ではないはず?)
[172]
第16面から第17面にまたがって、 U+0000 から U+FFFF
まで順に詰め込まれている。 >>55
[173] 漢字、ハングル音節、PUA、サロゲート符号位置も機械的に用意だけはしてあるようです。
[282]
超漢字V
の符号表
には
「
があります。説明を信じると、 >>647 で更新され、 それに続く >>651 でも更新され、 その次の >>649 では変更されていません。
があります。それぞれに2つの TrueType フォントが含まれます。
... との対応関係が定義されています。
... との対応関係が定義されています。
[626] Unicode と JIS との対応関係は、どちらのフォントも同じです。
[411] 2つ目の TrueType フォントのグリフは数個だけです。 >>308 の変更と対応していると思われます。
[412] >>414 にはこの他に、「固定」とされたフォントデータレコードが1つ、 「縦書」とされたフォントデータレコードが2つありますが、 どちらも空です。
[413] 「可変」であり、グリフごとに前進幅が異なります。
[507] 超漢字検索には TrueType 部分がこれらと同じ SSゴシックとSS明朝が入っています。
[534] 超漢字Vの「文字検索」小物では、 Unicode は各国と表示されます。 TRONコードと共に Unicode の符号位置の十六進数4桁が表示、指定できます。
16-2121 - 16-F648 : U+0000 - U+4DFFU+4E00 - U+9FA516-F649 - 16-C29D : 各国外16-C29E - 16-DBA9 : U+9FA6 - U+ABFF17-2121 - 17-996E : U+AC00 - U+D7FF17-996F - 17-AF5A : U+D800 - U+DFFF17-AF5B - 17-F362 : U+E000 - U+F8FFU+F900 - U+FA2D17-F363 - 17-F676 : 各国外17-F677 - 17-27C3 : U+FA2E - U+FFFF[543] URO / CJK互換漢字に相当する >>542 >>567 について、 「文字検索」の符号表では他の面の文字のいずれか各1つで補われる形になっています。 日本基本が優先と思われますが、詳しくは不明です。 日本基本, 日本補助, 中国基本, 韓国, 台湾, GT が使われます。中国拡張も使われるかもしれませんが、未確認です。
[535] URO / CJK互換漢字も16/17面の相当する範囲が確保はされています。 「TRON」モード (未割当部分) から辿れば字形なし、 Unicode 対応なしの空の符号表が見れます。 「各国」モードからもTRONコード指定で辿れますが、 境界部分で不思議な動きをします。無理に漢字を表示するための副作用でしょう。
[544] ハングル音節に相当する >>539 は「各国」に含まれ Unicode との対応関係がありますが、字形がありません。
各国4E00~ED63、F900~FA2D(ユニコード2.0に対応)に日本、中国、韓国、台湾、GTの中から1字を表示します。
ということで「文字検索」では Unicode 中にCJK統合漢字・CJK互換漢字も表示されるものの、各国併記になるらしい。 Unicode と各国規格および GT の対応関係を元に併記して、選択したらその規格の文字が挿入されるという仕様か?
CJK統合漢字のフォントを実装しようにも字形を1つ定められないから、 実装していないということかも。
[288] 超漢字V の 「超漢字サンプル集」→「多漢字・多文字の世界」→「世界のあいさつ」 に世界各地の言語と文字の例文があります。ほとんどは Unicode文字と思われます。
[289] bidi も shaping もなく表示順で並べているだけと思われ、 カーソル移動も編集もそのような挙動をします。
[290] フォントの品質もまーそんなもんかーという程度ですが、 時代を考えれば Unicode 2.0 が全部埋められるだけよく揃えたな、 と思えば立派なものかもしれません。
なお、超漢字に添付されている基本文章編集などのソフトウェアは、アラビア語やデヴァナガリ語などの言語固有の表記規則に対応しておりません。
[323] >>322 これは shaping しません、ということ?
Q.759 アラビア語などでletter同士を繋げて表示するにはどうしたらよいでしょうか?
[文字修飾]メニューの[比例ピッチ]を選びます。
[325] >>324 これはちょっとおもしろい。要するに標準の固定幅フォントなら連綿しないが、 可変幅フォントなら連続する、と。見た感じ特に特別なことはなく、 隣の文字とちょうど連続するような字形と文字幅の設計になっている模様。 (それだと組合せによっては繋がらなそうですが、未検証。)
[331] これについてはかつて関係者が
残念ながら超漢字の初期リリースにインド系言語の文字処理機構は登載されない注1)。しかし表示形(合字などの処理を施した後の文字)はそろっているので、文字としての表記は可能。
と説明していたそうです。 >>330 しかし当時それは実際には「そろってい」 なかったようですし、現在の超漢字Vにもそれらしきものは見当たりません。
と対応付けているようです。 >>580
[603]
BBB
は
ISO-8859-1 の [ 0xA0, 0xFF ]
をそのまま
[ 16-2263, 16-2364 ]
に対応付けているようです。
なお CR 領域は JIS X 0208 の〓となります。
>>580
[612] UTF-8 の ISO-8859-1 部分とはほとんどが違う変換になります。
[122] 未使用。
22-2121〜22-C25F 0x8140〜0xFE9F 23-624C〜23-C321 0x8431A439〜0x81308130
[153] >>82, >>299 : 634文字追加、 GB 18030 符号との対応表あり
[154] GBK の拡張分の領域がほとんど、2文字だけ4バイト領域。
[15] GB 18030 領域は634文字だけ割当てられており、 抜けがあります。 GSDP メーリングリストでの質問に対する PMC 担当者の回答によると、割当て (GB 18030 との対応?) は決まっていて、将来 (時期未定) フォントを追加することになっているようです。 >>31
[270] 超漢字内の符号表は 「中国簡体字」 に 「中国拡張漢字一覧」 なる一覧が付属しています。 1 から 634 まで、 「TRONコード」として 「23-545A」形式、 GB 18030 の十六進符号4桁ないし8桁、 Unicode の十六進符号4桁の表になっています。 >>258
[271] >>270 の収録内容は要検証ですが、22面が URO に対応し GB 18030 の2バイト符号に相当する漢字、 23面が CJK互換漢字に対応し GB 18030 の4バイト符号に相当する漢字2字です。
があります。説明を信じると、 >>647 で更新され、 それに続く >>651 >>649 では変更されていません。
があります。 2つの TrueType フォントがあり、 それぞれに 0x36 (22面) と 0x37 (23面) との対応があります。2つ目は追加分と思われます。
[505] 超漢字検索には TrueType 部分がこれらと同じ SS明朝 (TrueType 2個、計4個) が入っています。
[524] 超漢字Vの「文字検索」小物では、 GB 18030 が中国拡張と表示されます。 TRONコードと共に GB 18030 の十六進数の符号 (4桁または8桁) が表示、指定できます。 GB 2312 部分も含まれます (文字自体は中国基本に属するもので、 GB 2312 にあるもののみ)。 フォントで字形が表示できるのはごく一部だけですが、 TRONコードと GB 18030 の対応関係は、 該当部分の全体で表示されます。
1-2180 - 1-688F : 0xA1A1 - 0xFEFE (中国基本)22-2121 - 22-6262 : 0x8140 - 0xA1A022-6263 - 22-C260 : 0xA240 - 0xFEA022-C321 - 22-FDFD : 0x81308130 - 0x8336B33523-2121 - 23-624C : 0x8336B336 - 0x8431A439
- 「中国」(GB2312=GB18030 1区~ユーザ領域2)に、GB18030の3区以降を付け足して、GB18030全体をサポートしました。
- 「従来のGB2312の区点形式と、GB18030の16進数形式の両方で中国文字を指定できます。「中国拡張」では、最大8桁の16進数で、GB18030の全範囲(1区~四字節)を指定・表示できます。
これは「文字検索」の機能変更。
[176] 超�漢�字�4 R4.100B バ�ー�ジ�ョ�ン�ア�ッ�プ�版, , http://www.chokanji.com/download/ck4_100.html
TRON22面2121(8140)~TRON22面C25F(FE9F)と、TRON23面624C(8431A439)~TRON23面C321(81308130)を連続して表示します。
[124] 未使用。
[104] TRONコードの言語指定コードは、 言語や文字属を切り替えます。ただし、 実際に実装されている範囲内では、単なる面の切り替えに過ぎません。
なお「TAD言語環境と多国語対応」では「言語指定コード」というもので言語を切り替える、という構想が示されているが、現状で使用されている切り替えコードは言語指定コードではなく「スクリプト切り替えコード」だとされている(「TRONの多国語言語環境の仕様」, 『TRONWARE』Vol. 50, p. 47)。
[105] 1バイト目は 0xFE です。
その後に 0x21〜0x7E,
0x80〜0xFD の範囲の1バイトを使って指定します。
この2バイト目を 0xFE とすると、
更に言語指定コード列を続けることができます。
どれだけでも長くできるのかどうかは規定 BTRON3 になく、不明です。
| 第1面 | 0x21 | システムスクリプト面 | BTRON3, BRV-R4 |
| 第2面 | 0x22 | GT書体フォント2000 | BRV-R4 |
| 第3面 | 0x23 | GT書体フォント2000 | BRV-R4 |
| 第4面 | 0x2F | (予約) | BRV-R4 |
| 第5面 | 0x2F | (予約) | BRV-R4 |
| 第6面 | 0x26 | 中国伝統字スクリプト面 | BRV-R4 |
| 第7面 | 0x27 | 中国伝統字スクリプト面 | BRV-R4 |
| 第8面 | 0x28 | 大漢和辞典修訂二版 | BRV-R4 |
| 第9面 | 0x29 | 大漢和辞典修訂二版, 補巻, iモード絵文字 | BRV-R4 |
| 第10面 | 0x2A | 中国伝承文字、少数民族文字類 | BRV, BRV-R4 |
| 第11面 | 0x2B | (欠番)— 旧 今昔文字鏡スクリプト面 | BRV (欠), BRV-R4 (欠) |
| 第12面 | 0x2C | (欠番)— 旧 今昔文字鏡スクリプト面 | BRV (欠), BRV-R4 (欠) |
| 第13面 | 0x2D | (欠番)— 旧 今昔文字鏡スクリプト面 | BRV (欠), BRV-R4 (欠) |
| 第14面 | 0x2E | (予約)— 旧 今昔文字鏡スクリプト面 | BRV (予), BRV-R4 (予) |
| 第15面 | 0x2F | (予約) | BRV-R4 |
| 第16面 | 0x30 | Unicodeスクリプト面 | |
| 第17面 | 0x31 | Unicodeスクリプト面 | |
| 18〜31 | 〜0x3F | (予約) | BRV, BRV-R4 |
0x80 | Latin-1 (ISO/IEC 8859‐1) | 出典不明 |
[106] 昔の構想 出典不明:
[107] なぜ日本だけ語
がついているのか分かりませんが、
手元のメモ 出典不明 にそう書いてあるのでそのまま写しておきますね。
[108] 言語指定付き 出典不明:
0x40 | 日本文字属0 | 日本語 | システムスクリプト (JIS X 0208, JIS X 0212) |
0x41 | 日本文字属1 | 日本語 | 日本語スクリプト1 |
0x42 | 日本文字属2 | 日本語 | 日本語スクリプト2 |
0x43 | 中国文字属0 | 中国語 | システムスクリプト(中国GB) |
0x44 | 中国文字属1 | 中国語 | 中国語スクリプト1 |
0x45 | 中国文字属2 | 中国語 | 中国語スクリプト2 |
0x46 | 中国繁体文字属1 | 中国語 | 中国語スクリプト3 |
0x47 | 中国繁体文字属2 | 中国語 | 中国語スクリプト4 |
0x48 | 韓国ハングル文字属0 | 韓国語 | システムスクリプト (KS C 5601) |
0x49 | 韓国ハングル文字属1 | 韓国語 | 韓国語スクリプト1 |
0x4A | 韓国文字属0 | 韓国語 | システムスクリプト (KS C 5601) |
0x4B | 韓国文字属1 | 韓国語 | 韓国語スクリプト1 |
0x4C | 韓国文字属2 | 韓国語 | 韓国語スクリプト2 |
0x60 | 英語文字属 | 英語 | 各国スクリプト(ラテン文字) |
0x61 | フランス語文字属 | フランス語 | 各国スクリプト(ラテン文字) |
0x62 | ドイツ語文字属 | ドイツ語 | 各国スクリプト(ラテン文字) |
0xmm | 中国ピンイン文字属 | 中国語 | 各国スクリプト(ラテン文字) |
0xnn | 日本ローマ字属 | 日本語 | 各国スクリプト (ラテン文字) |
0xxx | アラビア文字属 | アラビア語 | 各国スクリプト (アラビア文字) |
0xyy | 発音記号属 | 発音記号 | 各国スクリプト (発音記号) |
[109] >>108 本気でこの調子で言語毎に番号を振っていくつもりだったのでしょうかね?
[110] >>108
韓国語で韓国文字
(漢字のことだと思われ。)
とハングルを分離しているのに、
日本語で仮名と漢字が分離されていないのはなんでだろう。
[111] 言語指定コードとは? - 超漢字ウェブサイト, http://www.chokanji.com/ckv/manual/01-07-02.html
[8] ISO/IEC 2022 の終端バイトと役割は似ています。
[9] Unicode言語タグとは異なります。
超漢字
[44] 第3章 TAD 詳細仕様書, , http://www.chokanji.com/developer/doc/btron3/shared_data/tad1.html#abq
[45] 第4章 フロッピーディスク形式, , http://www.chokanji.com/developer/doc/btron3/shared_data/fd_format.html#afd
[47] 3.6 図形描画セグメント, , http://www.chokanji.com/developer/doc/btron3/shared_data/tad3.html#aev
準TAD規格は、TAD規格に対して以下に示す変更/制限を行なったものである。
- 使用する文字コードは2バイトの固定長とし、 かつ第2バイトが先にくる形式とする。 1バイトの制御コードの直後には、常に値 "0" のバイトを詰めるものとする。 すなわち、 文字コードはリトルエンディアンの16ビットデータとみなす。
- 各セグメントのデータ構造として記述されている、 H, UH, W, UW, COLOR, UNITS, CHSIZE, SCALE, RATIO のデータタイプのバイトオーダーは、 下位バイトが先にくるリトルエンディアン形式とする。 UB タイプのデータには、 1.で記述した2バイト固定長の文字コードのみを使用する。
[46] 第4章 フロッピーディスク形式, , http://www.chokanji.com/developer/doc/btron3/shared_data/fd_format.html#agh
準標準フロッピーディスク形式は、 TRON 標準フロッピーディスク形式に対して以下に示す変更 / 制限を行なったものである。
- 使用する文字コードは2バイトの固定長とし、 かつ第2バイトが先にくる形式とする。 すなわち、文字コードはリトルエンディアンの 16 ビットデータとみなす。
- 2バイト以上のデータのバイトオーダーは、 下位バイトが先にくるリトルエンディアン形式とする。 文字列データには、1.で記述した2バイト固定長の文字コードのみを使用する。
[205] TADテキスト変換により、 JIS X 0208 以外の文字や一部の文字以外の TAD の情報を ASCII文字に符号化して文字列に埋め込む形で他システムを介した通信に使えました。
[38] SGML の文字参照風に表現したテキスト形式TRONコードがありました。
[206] 時系列的にはテキスト形式TRONコードが後から登場し、より簡便に使える方法として超漢字利用者の Web やインターネットメールの情報交換で使われていたようです。
[575] 符号化文字集合の各項で示した通り、 超漢字 では BTRONフォント形式の多数のフォントの集合体として実装されています。
[236] 利用者:٢١٩.١٧٤.١٥٨.٢٢٥ - Wikipedia, , https://ja.wikipedia.org/wiki/%E5%88%A9%E7%94%A8%E8%80%85:%D9%A2%D9%A1%D9%A9.%D9%A1%D9%A7%D9%A4.%D9%A1%D9%A5%D9%A8.%D9%A2%D9%A2%D9%A5#%E3%82%A6%E3%82%A3%E3%82%AD%E3%83%A1%E3%83%87%E3%82%A3%E3%82%A2%E3%82%B3%E3%83%A2%E3%83%B3%E3%82%BA
[237] >>236 ごく一部の文字のみ、字形画像が提供されています。
[242] tkx86_manual.pdf, , http://www.t-engine4u.com/archive/tkx86_manual.pdf#page=25
[576]
超漢字は、外部から Unix 風コンソールに接続できます。入出力は EUC-JP となっています。それ以外の文字は扱えないらしい、一部の ASCII 文字の扱いにも問題がある、雑な実装です。
[577] JIS X 0208 の文字のうち ASCII文字に相当するものは、 EUC-JP の ASCII文字に対応付けられています。
[578]
BBB は東アジアの主要な文字コード、ISO-8859-1、UTF-8 に対応しています。
[579] 表示している頁を保存することで、どう解釈 (変換) されたかを観測できます。
[580] ここでは、 HTML 形式 (TAD-HTML文書) の実身として保存したものによります。
[581]
不正・未対応の入力は、 1-222E (JIS X 0208 〓) になります。
btron:utf-8btron:gb2312btron:euc-jpbtron:euc-krbtron:shift_jisbtron:shift_jis-imodebtron:iso-8859-1btron:iso-2022-jpbtron:big5[284] 超漢字V の「超漢字」→「超漢字サンプル集」 →「フリーソフト・フリーデータ集」 → 「オフィスゼロ・プロデュース作品」 → 「コード変換パック」 は TAD とシフトJISやEUC-JPの変換ができるコンソール用ソフトウェアらしいです。
[9] TRON Code Utility ( 版) http://metanest.jp/tcu/tcu.xhtml
[20] TRONコードと ruby 1.9 M17n ( ( 版)) http://metanest.jp/btronclub/20110122/presen.html
[22] TRONコード - Wikipedia ( 版) https://ja.wikipedia.org/wiki/TRON%E3%82%B3%E3%83%BC%E3%83%89
[23] TRONコード ‐ 通信用語の基礎知識 ( 版) http://www.wdic.org/w/WDIC/TRON%E3%82%B3%E3%83%BC%E3%83%89
[24] 第2章 TRON コード体系 ( 版) http://www.chokanji.com/developer/doc/btron3/shared_data/tron_code.html
[159] 区点コードから漢字を探す - 超漢字ウェブサイト, , http://www.chokanji.com/ckv/manual/01-07-13.html
[160] 文字検索 - 超漢字ウェブサイト, , http://www.chokanji.com/ckv/manual/01-07-14.html
[161] コード一覧から探す - 超漢字ウェブサイト, , http://www.chokanji.com/ckv/manual/01-07-15.html
[162] 文字情報をみる - 超漢字ウェブサイト, , http://www.chokanji.com/ckv/manual/01-07-18.html
[34] 利用できる文字セット - 超漢字ウェブサイト ( 版) http://www.chokanji.com/ckv/manual/01-07-04.html
[43] レパートリー一覧, , https://web.archive.org/web/20041023203227/http://www2.tron.org/repertoire.html
TRONプロジェクトでは、2006年10月27日付けでTRONコードに下記の文字セットを更新いたしました。文字セット一覧を画像でご覧いただけます。
追加された文字セット
変体仮名
収録コード範囲 9面Bゾーン 8521〜8D7E
→文字一覧 1/2/3
※文字一覧2の表に誤りがありましたので修正しました。(2007年6月22日)
濁点付きひらがな・カタカナ (略称:濁点仮名)
収録コード範囲 9面Bゾーン 8021〜8230
→文字一覧 1
住民基本台帳収録変体仮名 (略称:住基仮名)
収録コード範囲 9面Bゾーン 8321〜846A
→文字一覧 1
TRON
[40] 超漢字Vで扱える文字 - 超漢字ウェブサイト, , http://www.chokanji.com/features/moji.html
[39] TRON多国語言語環境 (, ) http://umdb.um.u-tokyo.ac.jp/DKankoub/Publish_db/2000dm2k/japanese/01/01-07.html
[340] Article, , https://web.archive.org/web/20031018082138/http://www.btron.com/cgi-local/tips/bbs.cgi?num=194&ope=v&page=0
[350] Aprotool TM Editor Ver. 3.10 Help, , https://web.archive.org/web/20031006105401/http://www.ceres.dti.ne.jp/~maedera/TMEDIT/TMH_HIST.HTM
[50] Aprotool TM tips collection, , http://hp.vector.co.jp/authors/VA002891/APROTIPS.HTM#tip2
言語情報つき Unicode テキストや 準TAD形式の超漢字TRONテキストで作成されています。
[51] >>50 Aprotool TM Editor というソフトウェアが「正式TAD形式」と準TADの読み書きに対応していたそうです。
[351] Aprotool TM Editor Ver. 3.10 Help, , https://web.archive.org/web/20031006104318/http://www.ceres.dti.ne.jp/~maedera/TMEDIT/TMH_EXT.HTM
[55] TRON Code Utility, , http://metanest.jp/tcu/tcu.xhtml
[56] UNOFFICIAL TAD Guide Book ONLINE - TGBXX-1-0.pdf, , http://www.tad-wg.jp/tad-gb/tad-gb-dis/TGBXX-1-0.pdf#page=11
[57] ruby 1.9 でオレオレ文字コードを使う法, , http://metanest.jp/197x_3.html
[58] TRONコードと ruby 1.9 M17n, , http://metanest.jp/btronclub/20110122/presen.html
[61] グループ-ノート:GTコード - GlyphWiki, https://glyphwiki.org/wiki/Group-talk:GT%e3%82%b3%e3%83%bc%e3%83%89
[62] ノート:tron-8-2121 - GlyphWiki, https://glyphwiki.org/wiki/Talk:tron-8-2121
[66] User:٢١٩.١٧٤.١٥٨.٢٢٥~commonswiki - Wikimedia Commons, , https://commons.wikimedia.org/wiki/User:%D9%A2%D9%A1%D9%A9.%D9%A1%D9%A7%D9%A4.%D9%A1%D9%A5%D9%A8.%D9%A2%D9%A2%D9%A5~commonswiki
[72] Untitled Document, , http://tronweb.super-nova.co.jp/msgtolinuxhackers.html
[73] The Handling of Chinese Characters and TRON Code, , http://tronweb.super-nova.co.jp/chinesecharsandtroncode.html
[187] TRON多国語言語環境, , http://umdb.um.u-tokyo.ac.jp/DPastExh/Publish_db/2000dm2k/japanese/01/01-07.html
[188] 多国語・多漢字と文字コード, , http://umdb.um.u-tokyo.ac.jp/DPastExh/Publish_db/2000dm2k/japanese/01/01-06.html
[181] 超漢字は Unicode、各国規格、GT書体の対応・異体字データを持っているようですが、 一般公開はされていないようです。
[190] 39万文字の文字フォントセット「Tフォント」を参考出品します パーソナルメディアイベントブログ, , http://personalmedia.blog36.fc2.com/blog-entry-18.html
これによるとTフォントには 「康熙字典」 「甲骨文字」 「宋明異体字・金文釈文文字セット」 の文字があるらしい。 ということはそれがTRONコードのどこかの領域に割り当てられているはず。
しかし現在までに公表されたTフォントは従来のGT書体相当部分のみ.
[191] 東大・坂村研究室、約35万文字の漢字フォントを無償公開 (MYCOM PC WEB), , https://web.archive.org/web/20051215083203/http://pcweb.mycom.co.jp/news/2005/12/13/023.html
T書体フォントに含まれるのは、東京大学多国語処理研究会によって制定された「GT文字セット」の78,765字に加え、江戸時代および中国の宋・明・清時代の文献から抽出された漢字のうちGT文字セットに含まれない「宋明異体字」が34,499字、白川静著『金文通釈』を材料とした金文研究のための「金文釈文文字」661字、そして、変体仮名や、マンガの表現に見られる濁点仮名(「あ゛」を1文字で表したものなど)など非漢字文字1,814字の計115,739字。それぞれの字について「T明朝体」「Tゴシック体」「T楷書体」の3書体が用意されるので、公開されるフォントデータは合計約35万文字となる。
[210] TRON文字収録センター, , https://web.archive.org/web/20190407041403/http://charcenter.tron.org/
[225] >>210 GT書体とTフォントだけで、本来のTRONコードは消滅している。
[226] TRON文字収録センター, , https://charcenter.tron.org/
[227] >>226 更に少なくなってTフォントだけになった。
[232] >>228 TRONコードの後継でUnicodeの置き換えを目指すと謳って令和3年に発表された構想ですが、 少なくても公表されている限り、実態はほとんどないまま活動が停止しています。
[248] しかも「後継」は勝手に称しているだけで関係者ではなさそう。
[233] 3.4 tf.h (, ) http://www.chokanji.com/developer/doc/brightv.r4/library/lang/tf.html
[251] YellowRiverCon, , https://www.ne.jp/asahi/tron/music/YellowRiverCon.htm
[252] >>251 超漢字ウェブコンバータで作られた Webページ。
Shift_JIS であり、外字は普通の img の画像になっている。
[253] >>252 画像のファイル名は TRONコードを符号化したものなのかどうなのか?
[254] TRONとは?, , https://web.archive.org/web/20030227150216/http://homepage3.nifty.com/janee/_tYz33sJ.html
[255] >>254 超漢字ウェブコンバータで作られた Webページ。
[318] 超漢字3 ユーザー専用FAQ集, , https://www.chokanji.com/support/ck4/ck3ans/mail.html
なお、送信側、受信側ともに超漢字であっても、基本メールを使ってインターネットのメールサービスを利用する場合は、JIS第1/第2水準以外の文字を送受信できません。
[321] 超漢字2、超漢字(初代)ユーザー専用FAQ集, , https://www.chokanji.com/support/ck4/ck2ans/char.html#Q757
「超漢字」では、このTRONコードを採用しているため、これまでに活字化された文字は網羅的に含まれています。そのため、外字を扱う領域はございません。
一方、文字ではなく何かのマークやロゴを文章に混ぜたい場合があると思います。そのようなときには、基本図形編集で作った図形を文章に埋め込んでください。埋め込み図形は、文字と同じようにレイアウト、印刷可能です。また埋め込み図形をいったん最小に変形すると、回りの文字サイズに合わせて大きさが自動で調節されます。
[326] 詳細編:ご利用上の注意 | 超漢字検索ウェブサイト, パーソナルメディア株式会社, , https://www.chokanji.com/ckk/manual/notice.html
[337] Article, , https://web.archive.org/web/20040704184330/http://www.btron.com/cgi-local/tips/bbs.cgi?num=121&ope=v&page=0
[352] null, https://web.archive.org/web/20041107011044if_/http://homepage3.nifty.com:80/shinm/shed/troncode.txt
{kind=link}
{kind=link}